The Billion Rows Excel Challenge

Back in December 2021, How Fast is Fast Data Load in Power Query? demonstrated how long it took to load varying-sized datasets into the Data Model with and without Power Query’s Fast Data Load enabled.
What’s changed since then? Well, I got a new MacBook Pro, although I confess it’s been two years since I bought it, so it’s well past the honeymoon period now.
No, I don’t bother with Excel for Mac. I have Windows installed as a Parallels Desktop virtual machine – just so I can use the proper Excel. If you’re on macOS, I suggest you do the same.
Nevertheless, one regret from last time is I didn’t go as far as I could. Sure, I went up to 100 million rows of data, but there was potential to go much higher. After all, the Data Model’s theoretical limit is 1,999,999,997 rows.
Trust me, I did try.
Just before going to bed, I would start the process optimistic that I’d wake up hours later with a successful import.
However, there were a few issues:
- The files became so big I ran out of hard drive space.
- I repeatedly failed to allocate enough memory to the virtual machine.
- My previous MacBook Pro was prone to overheating, leading to system throttling and erratic behaviour.
Any errors thrown up were also very belated, which meant once I started the process, it was difficult to know if it was going to fail many hours later.
Preparation
I’m going to repeat the experiment for the same row categories as last time, except there’ll be two others: 500 million and 1 billion.
The same base data will be used: the 15-column fictional adult census datasets available from Kaggle. These CSV files have been combined to satisfy each row category using the same method as before.
For your information, I duplicated the 100 million file five times for 500 million and 10 times for 1 billion.
The final row categories and their respective file sizes are:
- 1 million: 136 MB
- 5 million: 701 MB
- 10 million: 1.34 GB
- 50 million: 6.9 GB
- 100 million: 13.5 GB
- 500 million (new): 69.5 GB
- 1 billion (new): 139 GB
If you want to know more about how I combined the datasets, please check out the original article.
Computer Specifications
Setup Then

15.4” MacBook Pro 2018
Operating system: macOS Monterey
CPU: 2.9 GHz 6-Core Intel Core i9
GPU: Radeon Pro 560X 4GB
RAM: 32 GB
Storage: 1 TB SSD
Windows 10 Virtual Machine Configuration
Processors: 2
Memory: 4 GB
Setup Now

16-inch MacBook Pro 2021
Operating System: macOS Sonoma
Chip: Apple M1 Max
CPU: 10-core
GPU: 32-core
RAM: 64 GB
Storage: 2 TB SSD
Windows 11 Virtual Machine Configuration
Processors: 4
Memory: 16 GB
In my previous experiment, I allocated 2 processors and 4 GB of memory to the virtual machine. However, I’m using different hardware this time, so it’s impossible to do a fair and equal test.
I decided to go with 4 processors, which is what Parallels recommends for my MacBook Pro.
Memory-wise, 16 GB is the same proportion as before. In other words, a quarter of the total available RAM.
I didn’t originally intend to use 16 GB, though. It was only after doing some test runs that I found 4 GB and 8 GB were not enough to handle the files with 500 million and 1 billion rows.
I thought it was better to be consistent across the board, so that’s why I went with that.
Watch the Action Unfold
Final Results
2021

2024

Final Results Comparison
Fast Data Load OFF

Fast Data Load ON

Woah! It’s Slower Than Last Time?
That’s correct — I was taken aback by the results myself. My current MacBook Pro easily has better hardware specs, so naturally, you’d think everything would be faster, right?
The reality isn’t that simple.
Let’s remember that this MacBook Pro is part of the much-lauded M1 chip family. First introduced in November 2020, it marked a significant shift in processing technology.
Unlike its predecessor Intel, which Apple used for about 15 years, M1 is based on ARM architecture instead of x86. This allows it to deliver high performance while maintaining low power consumption.
Furthermore, the integrated CPU, GPU, and RAM reduce the overhead communication between them, contributing to the performance gains.
However, emphasising hardware specs is all well and good, but there are other considerations. These include the number of assigned processors, how much memory is allocated to the virtual machine, and how optimised Parallels Desktop, Windows, and Excel are.
I did rerun some of the tests so I could be sure I was getting a similar result each time. I also tried memory allocations higher and lower than 16 GB, but with worse results, proving that 16 GB really is the sweet spot.
As for budging the virtual processors up or down from the recommended 4 — I didn’t. I’m sceptical it would have made any positive difference anyway.
I can only think that Parallels Desktop has not caught up yet in the silicon chip era, despite annual updates that claim to boost performance. It’s approaching four years now, but we could be waiting many more.
Observations
In a nutshell, there is a clear conclusion I’ve already alluded to: every 2024 result was slower than its 2021 equivalent.
What’s even more startling is despite Fast Data Load helping to slash the 2024 times, they were still slower than 2021’s with the option off.
In terms of time saved, there were no significant differences:
- 2021’s figures range from 18% to 33% (15% difference), whereas 2024’s range from 19% to 35% (16% difference).
- 2021’s figures average 26%, whereas 2024’s average 29%.
There’s a clear correlation between dataset size and time saved. However, as a percentage, the picture becomes murkier.
The first three results for 2021 are 31%, 24%, and 18%. This suddenly spikes to 23% and finally 33%.
Conversely, 2024’s are 31%, 33%, and 35%. Then there’s a sudden drop-off to 19% before increasing again to 28%. For the 500 million-row dataset, this extends to 34% but plummets to 26% for a billion.
Strangely, the middle datasets, which are 10 million for 2021 and 50 million for 2024, have the lowest percentages (18% and 19%) by a comfortable distance.
I’m not sure if this is a mere coincidence, but it definitely seems a little bizarre!
With Fast Data Load off, 2024’s times range from 30% to 53% slower (23% difference) than 2021’s. The average is 41%.
With Fast Data Load on, the range is identical, although the average is slightly lower at 39%.
Can This Data Actually Be Analysed?
That’s a reasonable question. Sure, it’s great to load a billion rows of data into Excel, but what’s the point if it’s impossible to analyse due to being a pure lagfest?
Last time, I only went up to 100 million, so I didn’t need to mention it. But the experience of working with that number isn’t very different to a million.
As you can see in the video from 6:20, I recorded the process from the very beginning, which started with opening the Queries & Connections pane. That took ~12 minutes, although it also had to load the other six queries.
After that, I followed the steps to insert a PivotChart & PivotTable, which allowed me to see the PivotChart fields in the pane.
I clicked on sex, triggering the two row labels, Female and Male, to immediately appear in a new PivotTable.
I then dragged this field into the Values box, and a column of count values was just as quickly added to the table.

Great! Although this was very simple analysis, at least I was able to make sense of one of the fields with virtually no lag whatsoever.
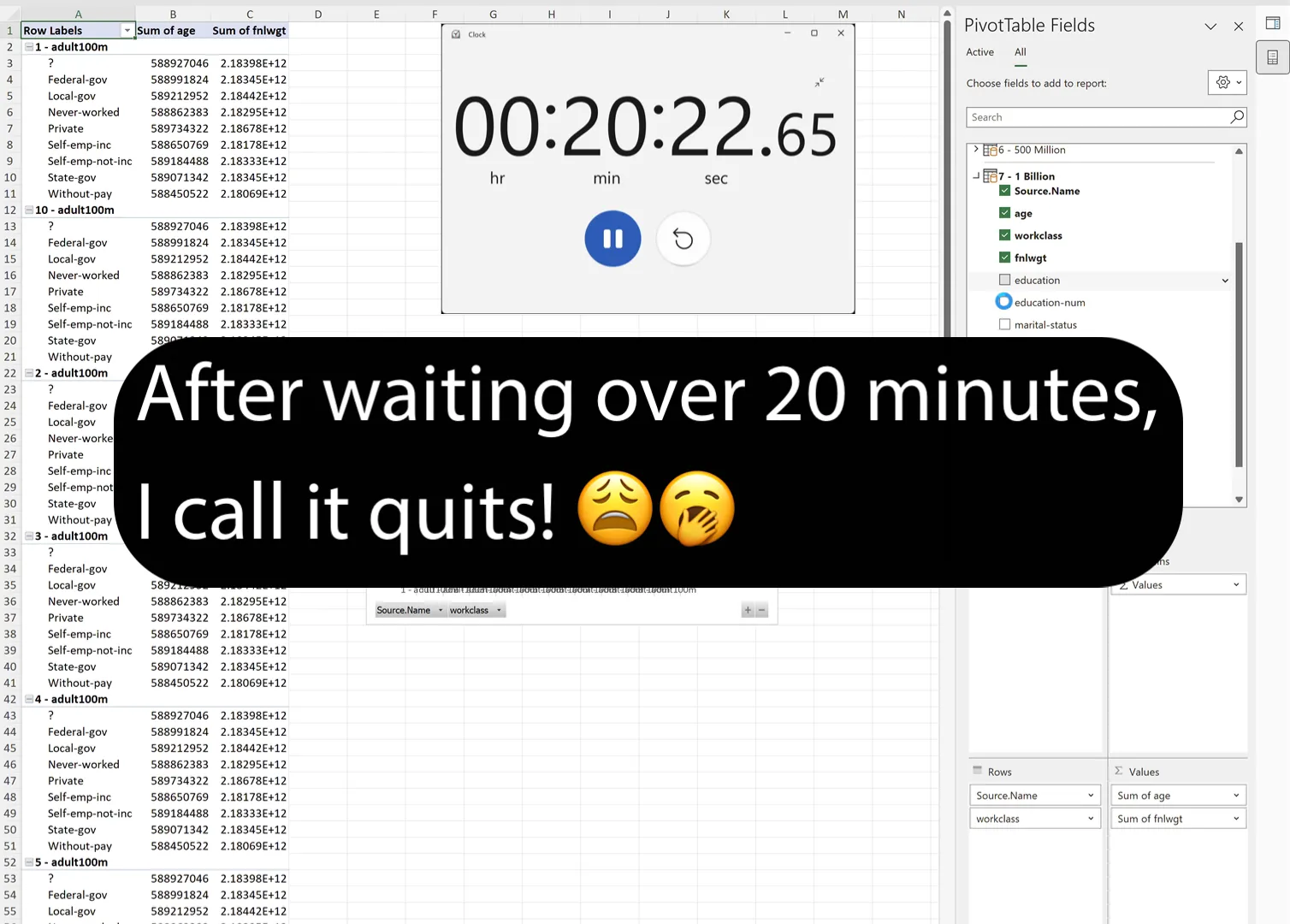
My next test was to see how many fields could run simultaneously. Predictably, the more checkboxes I ticked, the longer it took to update the PivotTable and PivotChart.
Interestingly, the difference between the fourth and fifth was massive. I’m talking about going from five seconds to over 20 minutes! I wasn’t prepared to wait any longer, so I brought the test to an abrupt halt.
The Billion Club
Am I the first person to attempt to load a billion rows into Excel? Of course not, although I almost certainly am to document it like I have!
Back in May, Mark Proctor attempted 1.024 billion rows. Astonishingly, he said in his LinkedIn post it took him “about 10 minutes”, which puts my result to shame. I don’t know much about Mark’s setup, but I do know he used a dedicated Windows computer.

I replied to Mark’s post, expressing my surprise. He responded by saying he loaded 16 CSV files comprising 64 million rows and two columns each. There were also “zero transformations” and “very few unique values”.
That’s interesting. My data also had zero transformations; however, it had 13 additional columns, meaning 13 billion more values. The data was also unique up to 100 million rows.
I guess that explains it. However, further investigation would be required to determine the extent of the difference it makes.
Final Words
If you watched the video, you’d be forgiven for thinking it was all plain sailing. In reality, there were a few bumps in the road to contend with.
Sometimes just opening the workbook was a big enough challenge.

Sometimes it was a memory allocation issue.
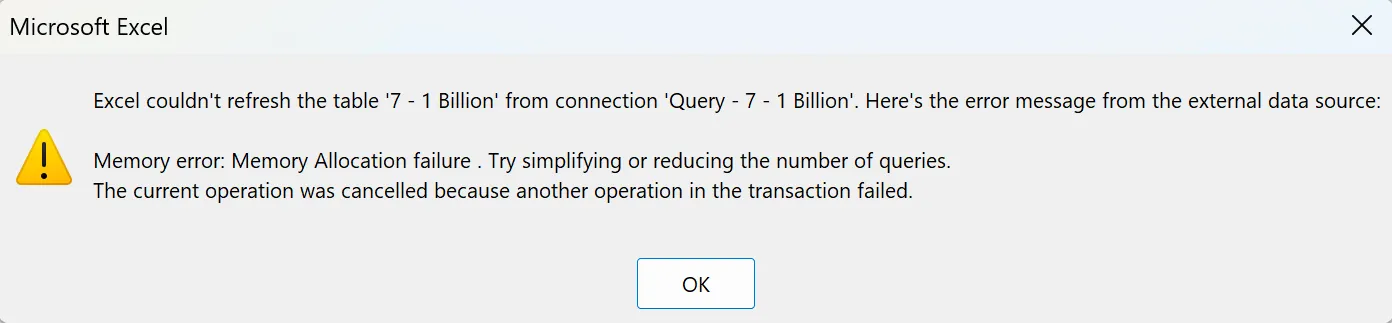
The truth is if you’re working with data remotely near as humongous as I went up to — expect problems. I know that my setup is hardly average, but even in a dedicated Windows 11 environment on a top-spec desktop computer, real-world analysis may prove tricky.
Unless you just want to brush the surface of your data (like I did), I would veer towards big data solutions like Hadoop or Spark. These have much greater speed, scalability, and reliability.
However, they are not simple plug-and-play tools, so they are best left to the experts!
I’m not saying you should go to the extremes I did, but it’d be interesting to see how long it takes you to load even a million or tens of millions of rows.
Excel on a modern computer with a reasonable spec can likely handle 100, 200, or 300 million rows of data without any obvious issues. So if you really want to, feel free to have a go yourself, and please report back if you do.
Oh, and let me finish by saying no. I won’t be attempting two billion rows anytime soon, so don’t suggest it!



























