Why can’t TEXTSPLIT be used with BYROW?

TEXTSPLIT and BYROW were both released earlier this year.
The former allows you to split a text value by a delimiter, whilst the latter applies a LAMBDA to each row and returns an array of the results.
Take a look at these examples.
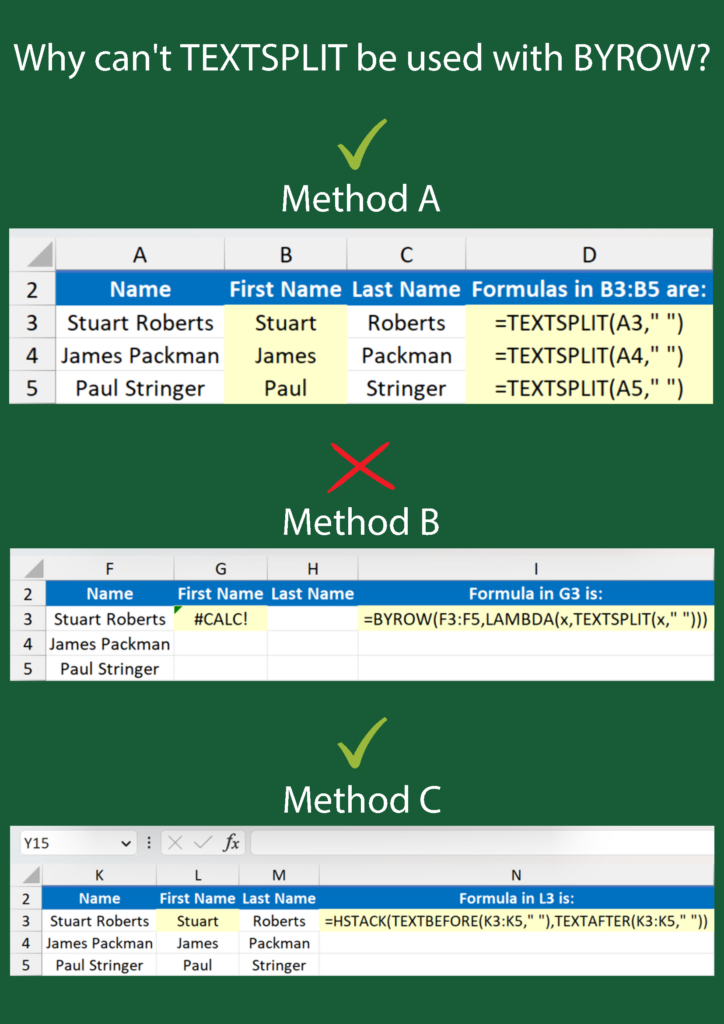
Method A shows the most basic way of using TEXTSPLIT. Each name is split into two columns with a formula for each row. This works fine, but it’s hardly an efficient approach by modern standards.
Method B is interesting, however. BYROW doesn’t seem to like TEXTSPLIT, even though everything in the formula seems right.
Method C is an alternative (although there are others) that uses TEXTBEFORE to extract the first name and TEXTAFTER for the last name. HSTACK then ensures these names spill horizontally. Again, it’s not the most efficient formula, though.
Does anyone know why TEXTSPLIT can’t be used with BYROW in the way shown? I am tempted to call it a glitch, but maybe there’s a good reason.




























Byrow,Bycol,Map, can’t handle formulas that return multiple values. So you can’t use inside them formulas that return more than one value, such as textsplit or filter (when filter returns more than one value).
Yeah, that seems to be the case, Ioan. Bit of a shame!
Hello
I had the same problem. You can solve it as follows, but all strings must have the same length.
'=LET( _Input, {"A|B|C", "1|2|3", "D|E|F", "4|5|6", "G|H|I", "7|8|9", "J|K|L", "0|1|2", "M|N|O", "4|1|9" }, _TextJoin, TEXTJOIN("|",,_Input), _TextDivide, TEXTSPLIT(_TextJoin, "|"), _BreakRow, WRAPROWS(_TextDivide,3), _BreakRow )